GULYÁS, Gábor György, Ph.D.
Blog
Az év információbiztonsági szakdolgozata cím Kovács Zoltáné! Gratulálok!
2017-09-18 | Gabor
(This post is exceptionally in Hungarian, as it is devoted to congratulate a former student of mine who won a national security thesis contest.)
Zoltán webes nyomkövetést és potenciális védekezést felmérő dolgozata nyertese lett a Hétpecsét Információbiztonsági Egyesület szakdolgozat pályázatának. Gratulálok!
Írtam hozzá egy kis kedvcsinálót:
Az internet de facto üzleti modelljét az az elképzelés adja, hogy az internethasználó a termék, aki el kell adni az ingyenes szolgáltatásért cserébe. Ennek technikai alapjául az ún. nyomkövetők szolgálnak, amelyek ma már szinte minden weboldalon megtalálhatóak, és csendben információt gyűjtenek a látogatókról. Az így gyűjtött adatok végül pedig adatbrókerekhez kerülnek, vagy célzott hirdetésekhez, dinamikus árazáshoz használják fel azokat. A dolgozat többek között arra a kérdésekre keresi a választ, hogy mennyire kiterjedt ez a megfigylés, illetve érdemben ellene-e lehet állni.
A szerző mérésekkel vizsgálja a népszerű privátszféra védelmi megoldások hatékonyságát, és általában az internethasználókon túl további alcsoportok, mint például a gyerekek vagy a magyar felhasználók milyen mértékben vannak kitéve az online megfigyelésnek. A dolgozat két módszert is körbejár az utóbbi kérdés megválaszolásra: elsőként az adatgyűjtést böngésző kiegészítő segítségével, majd a felhasználók böngészésének szimulációját. Végül a hatékonyság miatt a szerző az utóbbi eljárás mellett döntött, és az Alexa toplistáin lévő weboldalakon végzett mérésekre alapozva vizsgálta meg a privátszféra helyzetét.
A dolgozatból kiderül, hogy a gyerekek számára készült oldalakon kétszer annyi nyomkövető található, mint a felnőttekén. Ez a meglepő eredmény érdekes kérdéseket vet fel mind morális szempontból, mind pedig afelől, hogy a nyomkövetésben érintett cégek vajon hogyan készülnek fel a jövőre esedékes új adatvédelmi rendelet (GDPR) bevezetésére.
A dolgozat megtekinthető ezen a linken.
Kellemes olvasást kívánok!
Gulyás Gábor (konzulens)
Tags: web tracking, internet measurement, thesis contest
Amazon is an unfair market – unless you are a disguised robot
2017-06-30 | Gabor
When we visit webshops, we tend to have the perception that what we see is the ground truth that everyone else also sees, including products, services and prices. However, this is an illusion, as website functionality and pricing are highly customizable for personal preferences.
There are proven examples when companies tried to benefit from this illusion of their visitors – and below you can see two examples illustrating this. On the left, you can see online stores who used differentiated pricing, like for example, Amazon offered different prices based on the regions of their potential customers (source). On the right, a real example is provided by using a price-discrimination busting service, the Sheriff tool.
 Examples where personalized prices were found. [source]
Examples where personalized prices were found. [source]
 An exact example of personalized pricing: not all users get the same prices. [data collected via the Sheriff tool in 2016]
An exact example of personalized pricing: not all users get the same prices. [data collected via the Sheriff tool in 2016]
While there are still shops pursuing this practice,
Amazon stopped with it. But did you know that it still offers a tool for manipulating prices?
Amazon allows algorithmic pricing for vendors who use their platform. This means, that these sellers can use programs to automatically adjust their prices, even many times per day (at least not personalized prices!). Price changes can be triggered by many things, such as when their competitors change their prices, or according to a specific time of the day. Just like when gas stations raise prices when closing time approaches. Furthermore, this is not a lonely feature on Amazon, companies like RepriceIt or RepricerExpress are offering algorithmic price management services.
In a recent study (data from 2014 and 2015) researchers collected data on 1641 famous products, and they identified 543 sellers who seemed to be using algorithmic pricing. During the data collection period those sellers changed their prices many times of a given product (some even 100 or 1000 times!), usually adjusting to the price set by competitors or Amazon (who appears as a seller in this case).
This leads to a pretty unfair business practice by Amazon. Why? Well, let’s see:
Most people are not aware that dynamic pricing exists. Even more people do not know Amazon uses algorithmic pricing. The thing is that this system could be pretty easily be used against you, but you have a little chance to learn about it (so at the end you’ll leave more money on the table).
But even if you are aware, you could not do much. You can’t outcompete robots and it is not possible to track all prices all the time to know when it is a good deal.
But even if you were up to be using robots to see when prices drop, Amazon forbids you using robots to learn competitor prices. While in theory you could use scripts to crawl product profiles (like this), it is disallowed to learn competitor prices that way (checking pages like this). The
robots.txtsaysDisallow: /gp/offer-listingand they also technically enforce this policy.
But do not be surprised. In the same spirit, Amazon recently patented a technology that disabled price comparison when you visit their physical stores.
Tags: amazon, fairness, crawling, transparency
Measuring how browsers implement Content Security Policy
2017-04-20 | Gabor
Related to our recent project I started studing what is Content Security Policy (CSP) and how it works. In a nutshell, CSP is designed to protect website visitors against malicious activities. For example, if someone injects external scripts into a forum for some mal-intended reasons (like XSS or tracking), this could be prevented with CSP easily. The forum website only needs to declare that it does not accept external scripts. This need to be sent to the web browser as a header (before sending other content), which is something like this:
Content-Security-Policy: script-src www.my-forum.com;
Then if your visitors use a browser that implements CSP properly, malicious scripts or images (trackers) will be refused to load. CSP can also be used to protect content against unwanted embedding from www.my-forum.com (X-Frame-Options): third party websites will not be able to include scripts or to embed the whole site in an iframe.
While working on the project, first I had a naive implementation done on CSP, I observed strange (and rare) bugs. It seemed that the CSP reports – that we used for measuring the presence of web logins – sometimes didn’t arrive at all. Soon I started to wonder if I can still rely on my assumption that CSP implementations in different browsers works the same way.
Therefore I made a small tool to evaluate different implementations, and found interesting differences between implementations in differend browser brands. Furthermore, I also discovered a strange bug in the Chrome browser: sometimes it forgets to deliver CSP reports.
Tags: Content-Security-Policy, CSP, web security
New project: Browser Extension and Login-Leak Experiment
2017-04-05 | Gabor
This week we are excited to announce a new privacy-awareness raising project. We demonstrate how websites can detect two aspects of your online behavior:
- What extensions you have installed. For example, if you block ads by AdBlock Plus or whether you are trying to protect yourself from tracking using Ghostery or Disconnect.
- Which websites you are logged into. For example, websites can now whether you have entered your Gmail, Twitter or accessed your Facebook.
Websites may collect these pieces of information for various reasons; either to track you, or to learn more about you.
Fingerprinting beyond devices: your behavior
Why? Well, the main goal of online tracking is to identify website visitors across websites. Trackers recognize visitors by reading unique user’s identifier stored in cookies, or by identifying a unique collection of user’s device characteristics: this is called device fingerprinting. Such unique collection of device’s properties, or a fingerprint, can often uniquely identify the user who visited the website. Usually, fingerprint includes technical parameters like what browser and operating system a visitor is using, what timezone she is from or what fonts she has in her system.
Beyond pure technical characteristics, which are not explicitly chosen by the user, users can be identified by more “behavioral” characteristics, such as the browser extensions they installed and websites where they have logged in. Detecting extensions and website logins can clearly make a significant contribution to fingerprinting – and we would not like to arrive to the point, where websites can track us based on our behavior.
This would be especially worrisome for pro-privacy people:
the more extensions you install to your browser, the more trackable you are.
There could be more reasons for detecting your extensions and logins, which are beyond tracking (as tracking is mostly used for behavioral advertising and dynamic pricing). For example, a website would like to learn more about you by spying on your extensions and learning whether you have installed an adblock or not. With the method we featured in our test, this can be done even if the extension is disabled for the given page.
A website could also learn about your behavior and (somewhat private) preferences, in case you are logged in specific shopping, dating or health-related websites. Another possible scenario is if you work at a society, institution or a company that you don’t want the world to know. However, if you log in to your company intranet, there is a chance, that it could be detected and your workplace be learned. (Like for people working for Inria this can be detected, at least at the time of writing.) You might also not want to share with arbitrary websites that you are logged in to certain shopping sites, or to more sensitive services concerned with dating or your health.
What could we do about this?
The goal of our experiment is to change the status-quo by spreading the word about these issues to as many people as possible. This might not happen from one day to another, but we hope it will happen eventually – similarly as it happened for technical fingerprinting attacks, against which regular browsers now take countermeasures.
So, if you are interested, you can check out demo below, or you can read to know more about the details.

Browser Extension and Login-Leak Experiment: https://extensions.inrialpes.fr
Technical details on how it works
The extension detection technique exploits that websites can access browser extension resources. For example, a website can try to detect if Ghostery is installed in Chrome by trying to load its images (click to test) or if you have Adblock installed (click to test). These resources are called web accessible resources, and they are needed to provide a better user interface in the browser. In Chrome, extensions have less options to change the UI, thus more extensions use these resources (roughly 13k). In Firefox, extensions have more flexibility to the change the UI, making web accessible resources less common.
{kind=link}
{kind=link}
For the login detection we use two methods: redirection URL hijacking and we also use Content-Security-Policy violations. Let’s discuss them in this order.
Redirection URL hijacking. Usually, when you try to get access to a restricted page on a website, you are dropped to the login page if you are not logged in already. In order to make your life easier, these login pages remember the URL of the rejected page, and they plan to drop you there after logging in properly. This is where our attack comes in: we change this URL, so you’ll land on an image if already logged in.
More technically speaking, if we embed an <img> tag pointing to the login page with the changed URL redirection, two things can happen. If you are not logged in, this image will fail to load. However, if you are logged in, the image will load properly, and we can detect this, even though we are a third-party site here.
Abusing Content-Security-Policy violation for detection. Content-Security-Policy, or CSP in short, is a security feature designed to limit what the browser can load for a website. For example, CSP can be easily used to block injected scripts on forums. If there is an attempt like that, the resource will not load, and the browser can also be instructed to report such violation attempts to the server backend.
However, we can also use this mechanisms for login detection, if there are redirections between subdomains on the target site depending on whether you are logged in or not. Similarly, we can embed an <img> tag pointing to a specific subdomain (and page) on the target website, just wait if a redirection happens or not (which would violate our artificial CSP constraints).
Advices for self-protection
If you want to protect yourself from websites seeing which extensions you use, the only advice we can give for the moment is to switch to another browser. For example, in Firefox only few extensions are detectable. You could use other browsers too, but we can’t tell which one would be the best in terms of protection: it has not yet been evaluated.
The good news are: blocking login detections is easy – all you need to do is to disable third party cookies in your browser. Some tracking blocking extensions, such as Privacy Badger could also help – but don’t forget: the more extensions you install, the more trackable you’ll be.
I am thankful to Nataliia Bielova reviewing a draft version of this post.
Tags: privacy, tracking, fingerprinting, logins, extensions, demo
Re-identification explanation and an intuitive in-browser demo for social networks
2017-01-09 | Gabor
In our recent paper, we proposed a novel social network de-anonymization attack, which had pretty nice results when compared with others. I made a program, where the original attack and ours can be tested out, directly in the browser. This means that you can run re-identification attacks even on your smartphone… :) Check it out:
Just runs the simulator.
Takes you there with explanation.
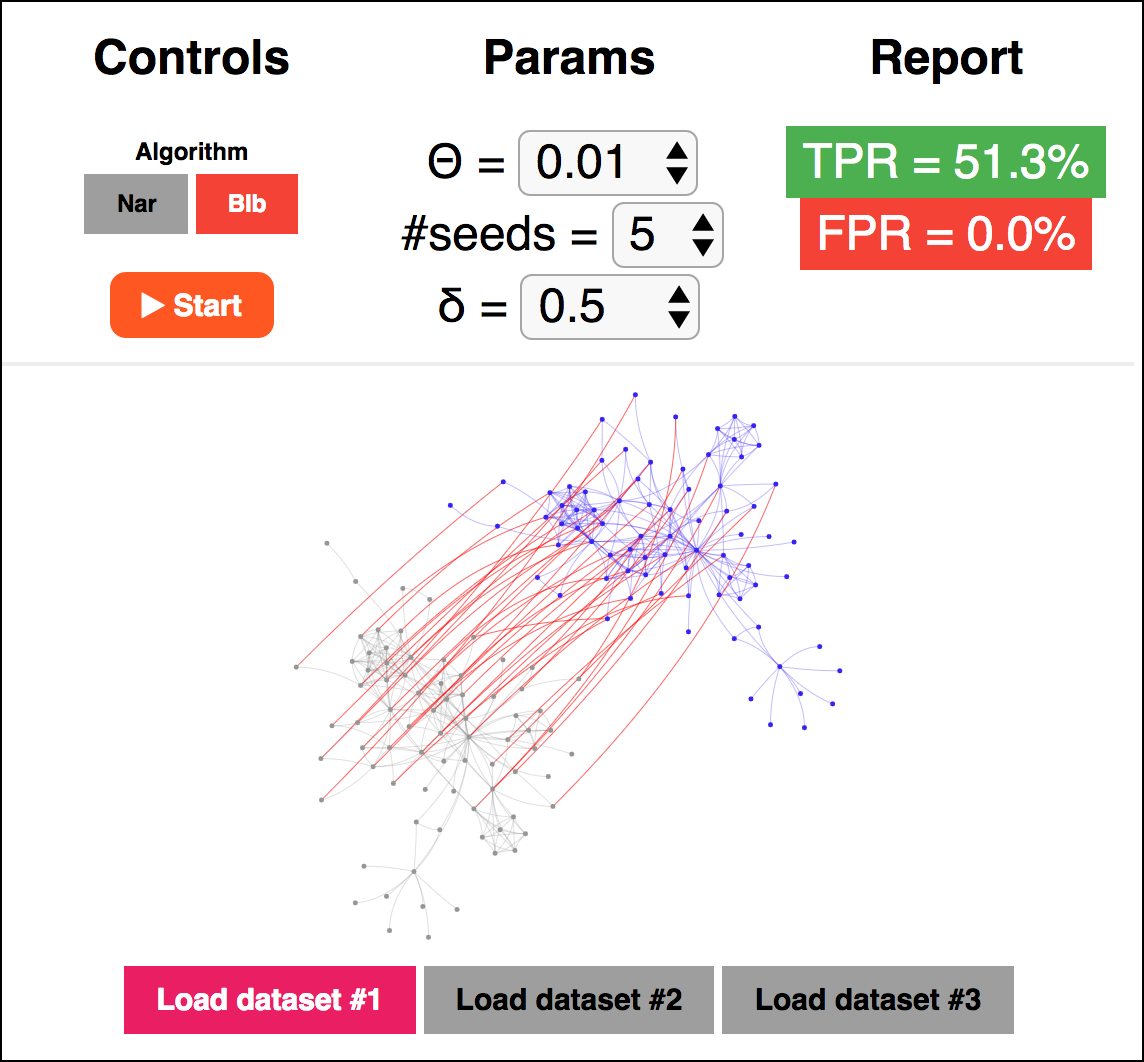
Tags: social network, privacy, de-anonymization, simulation
Blog tagcloud
CSP (1), Content-Security-Policy (1), ad industry (1), adblock (1), ads (1), advertising wars (1), amazon (1), announcement (1), anonymity (9), anonymity measure (2), anonymity paradox (3), anonymity set (1), boundary (1), bug (2), code (1), control (1), crawling (1), data privacy (1), data retention (1), data surveillance (1), de-anonymization (2), definition (1), demo (1), device fingerprint (2), device identifier (1), disposable email (1), ebook (1), el capitan (1), email privacy (1), encryption (1), end (1), extensions (1), fairness (1), false-beliefs (1), fingerprint (3), fingerprint blocking (1), fingerprinting (3), firefox (1), firegloves (1), font (1), future of privacy (2), google (1), google glass (1), home (1), hungarian keyboard layout (1), inkscape (1), interesting paper (1), internet measurement (1), keys (1), kmap (1), latex (1), location guard (1), location privacy (1), logins (1), mac (1), machine learning (3), neural networks (1), nsa (2), osx (2), paper (2), pet symposium (2), plot (1), price of privacy (1), prism (1), privacy (8), privacy enhancing technology (1), privacy-enhancing technologies (2), privacy-enhancing technology (1), profiling (2), projects (1), raising awareness (1), rationality (1), re-identification (1), simulation (1), social network (2), surveillance (2), tbb (1), thesis contest (1), tor (1), tracemail (1), tracking (12), tracking cookie (1), transparency (1), tresorit blog (4), uniqueness (3), visualization (1), web bug (3), web privacy (3), web security (1), web tracking (3), win (1), you are the product (1)